6月11日,字节跳动(以下简称“字节”)旗下火山引擎举办Force原动力大会,发布豆包大模型1.6、视频生成模型Seedance 1.0 pro等新模型,并上线火山引擎AI云原生系列产品,包括升级后的Agent(智能体)开发平台,多模态数据湖,AI基础设施的Agent套件、训练套件、推理套件等,以帮助To B客户更好地构建生产级Agent。
这也意味着,在AI Agent规模化商用元年,国内第一梯队的四大玩家悉数亮相完毕。
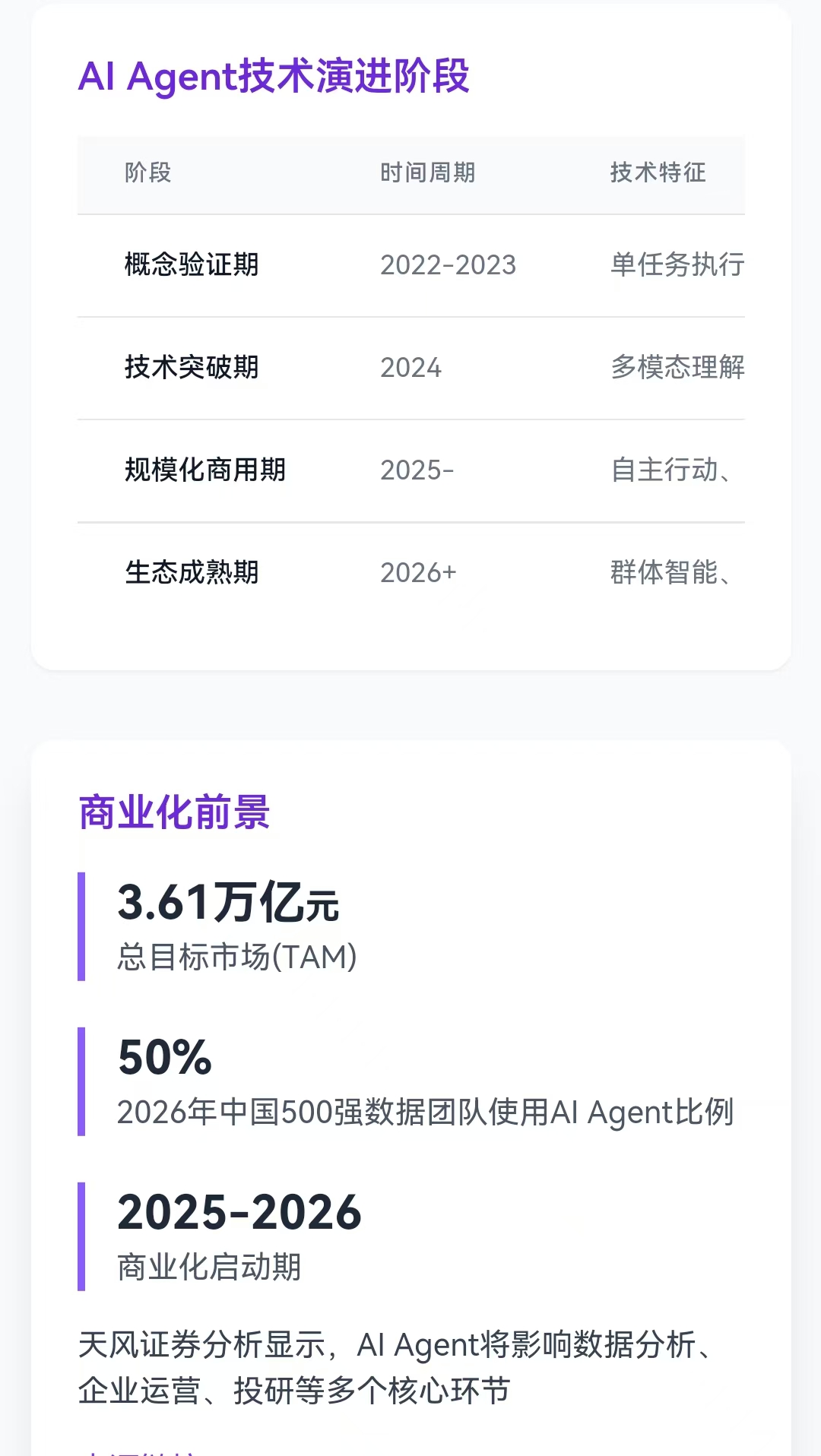
4月底,百度(09888)创始人李彦宏在武汉率先出手,表示大模型应用落地的春天已经到来,要全面拥抱MCP(模型上下文协议)。5月21日,腾讯控股(00700)旗下腾讯云发布智能体开发平台;随后,阿里巴巴集团(09988,以下简称“阿里”)CEO吴泳铭,在阿里云出海大会上表示,阿里云将在三个方面加大投入:第一,加速打造全球云计算一张网;第二,加速模型出海,加速AI产品国际化;第三,打造海内外一体的最优服务体验。
据IDC报告,作为坐拥中国公有云大模型市场46.4%份额的头部玩家,豆包大模型“压轴”出手虽稍晚几天,却也是最“软硬兼施”“秀肌肉”的:技术能力上,豆包已涵盖多模态、视频、图像、语音、音乐等模型品类,豆包1.6模型在复杂推理、竞赛级数学、多轮对话和指令遵循等测试集上均跻身全球前列;行业应用上,豆包大模型已服务全球TOP10手机厂商中的9家、8成主流汽车品牌、70%的系统重要性银行及超5成985高校;AI Agent“价值战”普惠上,豆包大模型1.6采用创新的“区间定价”,客户使用成本降至三分之一,全方位推进智能提升和应用落地。
“PC时代主体是Web,移动时代是App,AI时代则是Agent。Agent能够自主感知、规划和反思,完成复杂任务。从被动工具转变为主动执行者。豆包大模型和AI云原生将持续迭代,助力企业构建和大规模应用Agent。”火山引擎总裁谭待认为,AI时代已推动开发范式与技术架构的全面升级,而只有通过技术和商业的双重创新,才能推动Agent的规模化应用。
而面对行业头部玩家的拼投入、拼研发、拼生态等的“拼刺刀”,字节CEO梁汝波表示:“字节致力成为优秀的创新科技公司,会坚定长期投入,追求智能突破,服务产业应用。通过火山引擎,持续把新模型、新技术开放给企业客户。”
池大鱼大,AI普惠战略升级
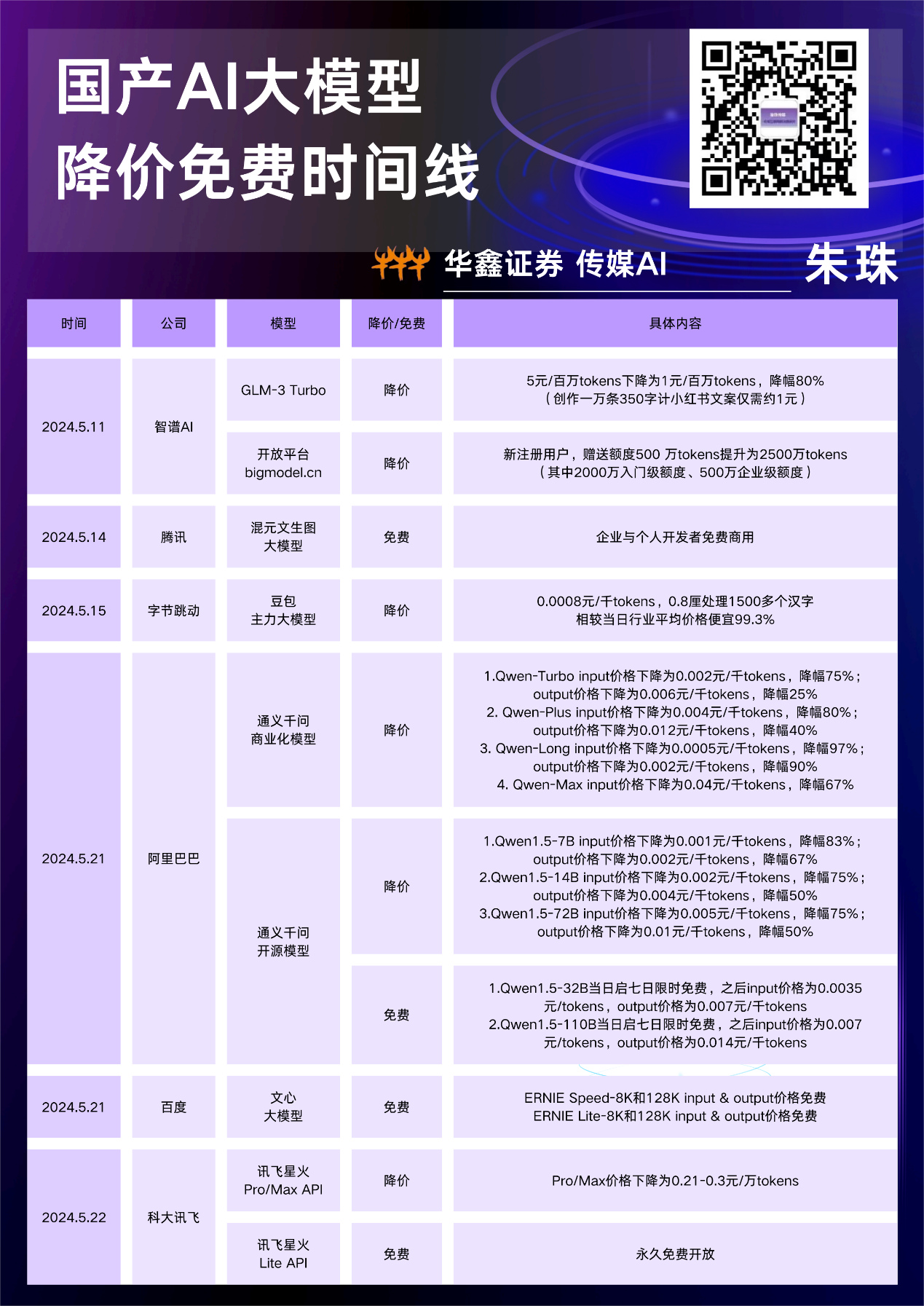
2024年5月15日,火山引擎曾通过主力大模型降价,掀起了大厂主力大模型的降价潮。
当日发布会上,火山引擎宣布升级火山方舟、应用服务、机器学习平台、云底座的同时,一口气发布9款大模型,并巨幅调降主力大模型调用价格:豆包pro 32k模型推理输入定价降至0.0008元/千tokens(文本基本处理单元),较同业价格“断崖式”下降99.3%;豆包pro 128k模型正式定价0.005元/千tokens,较同业价格低95.8%。
虽然在豆包大模型降价前,国内大模型“六小虎”之一的智谱AI,早在5月11日就宣布了降价,将入门级大模型GLM-3-Turbo(上下文长度128k)的价格从0.005元/千tokens降低到0.001元/千tokens,开放平台新注册用户获赠从500 万tokens提升至2500万tokens(包含2000万入门级额度和500万企业级额度),但豆包的入场,仍是百度、阿里、腾讯等大厂全面跟进的“始作俑者”。
豆包降价后的5月21日,阿里云宣布通义千问主力模型Qwen-Long直降97%(0.0005元/千tokens)。降价后,阿里通义模型约为GPT-4价格的1/400,击穿全球tokens底价的同时,较之5月15日豆包大模型的0.0008元/千tokens,价格又降了30%+。同日,百度宣布文心大模型的两款主力模型ENIRE Speed、ENIRE Lite即刻起全面免费,开启大模型API调用的“免费时代”。百度相关负责人还特意强调称,这两款模型支持128k、8k上下文长度,是目前百度文心大模型系列中服务用户最多的模型型号。
一天后的5月22日,腾讯云将主力模型之一的混元-lite模型调整为全面免费;万亿参数模型混元-pro,API(应用程序编程接口)输入价格从0.1元/千tokens降至0.03元/千tokens,降幅达70%。同日,大模型“国家队”科大讯飞(002230)发布公告称,讯飞星火API能力正式免费开放。其中,讯飞星火Lite API永久免费开放,讯飞星火Pro/Max API低至0.21元/万tokens。
彼时,谭待在受访中公开表示,“(豆包降价)一是能做到,二是需要这么做;主力模型比行业便宜99.3% 在技术上可实现,未来还有很多手段降低成本”,而且豆包分布式推理还有混合调度,通过发挥各种各样的异构算力解决了推理算力问题,进而可以把模型推理的成本降到很低。
“以前企业做创新担心 ROI (投资回报率)打不正,一来创新项目90%会失败,二来创新按消耗100 亿Tokens 算就要80万元;现在成本只需要8000元,失败也花不了多少钱,但剩下10%项目成功就可以把投入都赚回来,这无疑能帮助更多企业轻装上阵,无负担投身 AI 大潮。”谭待说。
也正是基于此,在豆包跨过模型效果、推理成本、落地难度三道基本门槛后,把“蛋糕做大”成了火山引擎举起价格“屠刀”的根本用意所在。
“对于大模型创业者来说,没有哪家能靠To B业务赚很多钱,或者可以认为通过To B 服务把自己的大模型商业模式正循环此路不通。而现在还是大模型创业特别早期的阶段,池塘大鱼才大,要把蛋糕做大先要做到普惠,让很多企业能以更低成本做各种创新,这是更重要的。”谭待称。
大模型一年来的飞速发展也表明,火山引擎堪称是2024年国内大模型“唯二”影响了行业发展走向的公司之一,另一家是2024年底的DeepSeek。
数据显示,豆包大模型日均Tokens调用量从2024年12月的4万亿飙升至2025年5月的16.4万亿,年增长率超300%,较2024年5月首次发布时增长137倍;稳居中国公有云大模型服务调用量第一,46.4%的市场份额超行业第二第三之和。
领先的市场份额之外,豆包模型企业级应用场景快速扩展、广泛分布。AI 搜索、编程、视觉理解等场景Tokens消耗5个月增长4.4倍,其中K12在线教育增长12倍,智能巡检、视频检索等新场景突破日均百亿Tokens。
“豆包大模型1.6的价格体系,是火山引擎以技术创新为杠杆,打破行业定价规则,让企业以更低成本获取更强AI能力。正如豆包1.0开启了大模型规模调用时代,豆包1.6将加速Agent的大规模落地,推动AI真正成为企业增长的核心引擎。”谭待说,也正是从这个角度看,豆包大模型调用成本再降至原价1/3,既是火山引擎AI普惠的战略升级,更是Agent商用加速推广的“价值战”而非“价格战”。
技术驱动,首创“区间定价”模式
之所以认为此次降价是“价值战”而非简单的“价格战”,加快Agent商业落地的原因之外,还有火山引擎通过技术驱动、首创大模型行业“区间定价”的引领意义。
IDC数据显示,2024年中国AI Agent市场规模仅50亿元,远低于预期,反映出企业对高成本的观望心态。而这一现象的核心矛盾在于模型价格与企业实际需求的错配。行业统计表明,企业级Agent的实际应用成本压力相当突出——单个Agent每日token消耗成本可达20美元。
据谭待介绍,以往的模型定价机制,是按大模型按tokens收费,输入输出的tokens数量直接决定成本。例如,输入1000字的中文文本约生成1500个tokens,而输出1000字则需约1500个tokens。这种计费模式下,上下文长度是成本的核心变量,而非模型是否开启深度思考或多模态功能。
考虑到大模型的运行还有其“成本递增效应”(随着上下文长度增加,模型处理每个token的计算复杂度呈指数级上升),则单token的成本会更高。例如,有些模型在处理超过128K tokens时收费翻倍,因其注意力机制需与前文所有tokens进行关联计算。
而火山引擎统计发现,当前,超过80%的企业调用请求集中在32K tokens以内。若能针对这一主流区间优化调度,可显著降低企业整体成本。
基于此,火山引擎通过深度技术优化,首创豆包大模型1.6的“区间定价模式”,以精准匹配企业需求分布,实现企业Agent成本与性能的双重突破。
“首先,我们打破行业惯例,采用统一定价,无论客户是否开启深度思考或多模态功能,豆包大模型1.6的token价格完全一致,让客户能够以基础语言模型的价格享受到高级功能。”谭待告诉《财中社》,“其次,火山引擎通过分桶调度,精准匹配客户需求,降低客户调用成本。”

谭待以企业主力需求的0-32K区间场景举例分析称,豆包大模型1.6输入百万tokens定价仅0.8元,输出百万tokens定价8元。以输入输出比3:1计算,综合成本仅为2.6元/次,较豆包1.5 thinking和DeepSeek R1(综合成本7元/次)下降62.9%。豆包1.6大模型调用成本降至豆包1.5深度思考模型或DeepSeek R1的三分之一。Seedance 1.0 pro模型每千 tokens仅0.015元,每生成一条5秒的1080P视频只需3.67元,为行业最低。
这其中,“分桶调度”技术的优化至关重要。通过分桶调度,豆包1.6将80%的请求导向0-32K主力需求区间,利用短文本处理的高并行性提升效率,降低单位成本。
当然,通过多模态原生支持,免掉客户额外付费,按需调用图文、音视频等多模态能力,且性能优于豆包1.5和DeepSeek R1;依托火山引擎与字节国内业务并池的算力成本规模效应,同款GPU配置价格低于行业平均水平等举措,同样是客户低价获取高性能服务的关键。
此外,针对输入32K、输出200 tokens以内的请求,豆包1.6输出价格进一步降至2元/百万tokens,与豆包1.0持平,延续超低门槛,也是火山引擎通过设立特惠专区、覆盖客户非思考需求的“普惠”举措组成部分。
而为了更好地支持Agent开发与应用,火山引擎AI云原生全栈服务升级,发布了火山引擎MCP服务、PromptPilot 智能提示工具、AI知识管理系统、veRL强化学习框架等产品,并推出多模态数据湖、AICC私密计算、大模型应用防火墙,以及一系列AI Infra套件。
“深度思考、多模态和工具调用等模型能力提升,是构建Agent的关键要素。同时,由于Agent每次执行任务都会消耗大量tokens,模型使用成本的降低,才能推动Agent的规模化应用。”谭待表示。
“中美作为唯二的人工智能玩家,形成了非对称的技术路径——中国更重视下游应用。想要发挥我们的比较优势,就要降低应用开发的成本,而大模型的降价无疑最为直接。”东吴证券(601555)研究所计算机行业首席分析师王紫敬告诉《财中社》。




网友留言(0)